Note: This article was first published on Moz Blog. This version does not use hypotext functionality and will be used to test the performance of hidden content in Google’s search.Question: How does a search engine interpret user experience?
Answer: They collect and process user behaviour data.
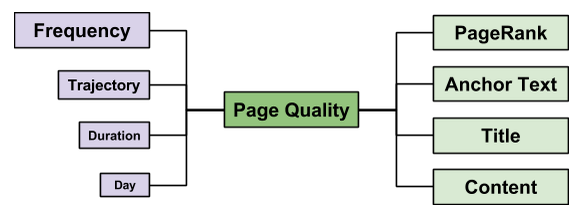
Types of user behaviour data used by search engines include click-through rate (CTR), navigational paths, time, duration, frequency, and type of access.
Click-through rate
Click-through rate analysis is one of the most prominent search quality feedback signals in both commercial and academic information retrieval papers. Both Google and Microsoft have made considerable efforts towards development of mechanisms which help them understand when a page receives higher or lower CTR than expected.
For example, user reactions to particular search results or search result lists may be gauged, so that results on which users often click will receive a higher ranking. The general assumption under such an approach is that searching users are often the best judges of relevance, so that if they select a particular search result, it is likely to be relevant, or at least more relevant than the presented alternatives.
Source: Google, 2015
To get an idea of how much research has already been done in this area, I suggest you query Google Scholar.
Position bias
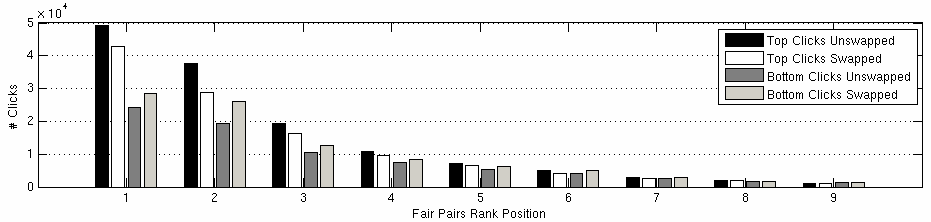
CTR values are heavily influenced by position because users are more likely to click on top results. This is called “position bias,” and it’s what makes it difficult to accept that CTR can be a useful ranking signal. The good news is that search engines have numerous ways of dealing with the bias problem. In 2008, Microsoft found that the “cascade model” worked best in bias analysis. Despite slight degradation in confidence for lower-ranking results, it performed really well without any need for training data and it operated parameter-free. The significance of their model is in the fact that it offered a cheap and effective way to handle position bias, making CTR more practical to work with.
Search engine click logs provide an invaluable source of relevant information, but this information is biased. A key source of bias is “presentation order,” where the probability of a click is influenced by a document’s position in the results page. This piece focuses on explaining that bias, modeling how the probability of a click depends on position. We propose four simple hypotheses about how position bias might arise. We carry out a large data-gathering effort, where we perturb the ranking of a major search engine, to see how clicks are affected. We then explore which of the four hypotheses best explains the real-world position effects, and compare these to a simple logistic regression model. The data is not well explained by simple position models, where some users click indiscriminately on rank 1 or there is a simple decay of attention over ranks. A “cascade model,” where users view results from top to bottom and leave as soon as they see a worthwhile document, is our best explanation for position bias in early rank.
Source: Microsoft, 2008
Result attractiveness
Good CTR is a relative term. A 30% CTR for a top result in Google wouldn’t be a surprise, unless it’s a branded term; then it would be a terrible CTR. Likewise, the same value for a competitive term would be extraordinarily high if nested between “high-gravity” search features (e.g. an answer box, knowledge panel, or local pack).
I’ve spent five years closely observing CTR data in the context of its dependence on position, snippet quality and special search features. During this time I’ve come to appreciate the value of knowing when deviation from the norm occurs. In addition to ranking position, consider other elements which may impact the user’s choice to click on a result:
Snippet quality
Perceived relevance
Presence of special search result features
Brand recognition
Personalisation
Practical application
Search result attractiveness is not an abstract academic problem. When done right, CTR studies can provide a lot of value to a modern marketer. Here’s a case study where I take advantage of CTR average deviations in my phrase research and page targeting process.
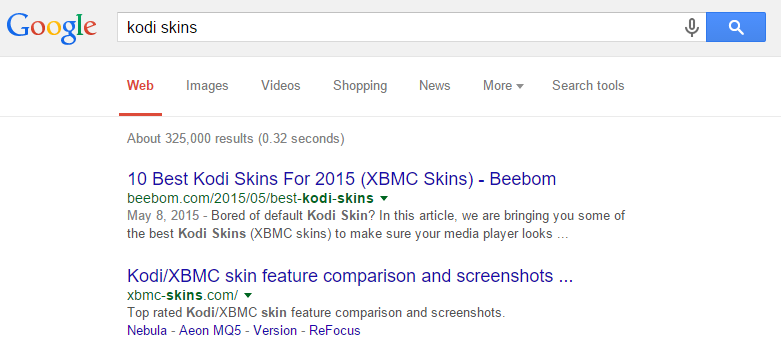
In the graph below, we see position-based CTR averages for xbmc-skins.com retrieved from Google’s Search Console:
The site caught my attention, as it outranks the official page for a fairly competitive term. Mark Whitney (the site owner) explains that people like his website better than the official page or even Kodi’s own skin selection process and often jump on his site instead of using the official tools simply because it provides a better user experience.
“There was no way to easily compare features and screenshots of XBMC/Kodi skins. So I made the site to do that and offer faceted filters so users can view only the skins that suit their requirements.”
If a search query outperforms the site’s average CTR for a specific position, then we’re looking at a high-quality snippet or a page of particularly high interest and relevance to users. After processing all available data, I’ve identified a query of particularly good growth potential. The phrase “kodi skins” currently ranks at position 2 with a CTR of 39%, as opposed to the 27% expected from that position. That’s 12% more than the average CTR for this domain. Part of that success can be attributed to a richer search snippet with links to the most popular skins. One of the reasons for the links to appear in the first place was, of course, user choices, from both a navigational (page visits, navigational paths) and an editorial point of view (links, shares and discussion). It’s a powerful loop.
With this information, I was able to project a more optimistic CTR for position #1 in Google and inflate traffic projection up to 3,758 clicks. The difficulty score for the result above us is only 23/100, which, in combination with expected click gain, shows an amazing potential score of 831. Potential score is a relative value, and represents a balance between difficulty and traffic gain. It’s critical when prioritising lists of hundreds or even thousands of keywords. I usually just sort it by potential and schedule my campaign work top-down.
After mapping all keywords to their corresponding landing pages, I was able to produce a list of high priority pages ordered by the total keyword potential score. At the top of the list are pages guaranteed to bring good traffic with low effort, and at the bottom of the list are pages that will either never move up, or the extra traffic won’t be attractive enough if they do.
Additional factors
By aggregating position-based CTR data from multiple reports, I ended up with an up-to-date CTR trends graph for 2015. It shows an interesting dip at position 5, likely influenced by high-gravity SERP elements (e.g. a local pack):
Separating branded and non-branded terms gave me different results, showing much lower CTR values for the top three positions. Finally, URL mapping and phrase tagging also allowed me to determine averages for:
Page type
Page topic
Language
Location
File format
Google’s title bolding study
Google is also aware of additional factors that contribute to result attractiveness bias, and they’ve been busy working on non-position click bias solutions.
Leveraging click-through data has become a popular approach for evaluating and optimizing information retrieval systems. For instance, since users must decide whether to click on a result based on its summary (e.g. the title, URL, and abstract), one might expect clicks to favor “more attractive” results. In this piece, we examine result summary attractiveness as a potential source of presentation bias. This study distinguishes itself from prior work by aiming to detect systematic biases in click behavior due to attractive summaries inflating perceived relevance. Our experiments conducted on a commercial web search engine show substantial evidence of presentation bias in clicks, leaning in favor of results with more detective titles.
Source: Google, 2010
They show strong interest in finding ways to improve the effectiveness of CTR-based ranking signals. In addition to solving position bias, Google’s engineers have gone one step further by investigating SERP snippet title bolding as a result attractiveness bias factor. I find it interesting that Google recently removed bolding in titles for live search results, likely to eliminate the bias altogether. Their paper highlights the value in further research focused on the bias impact of specific SERP snippet features.
“It would be interesting and useful to identify more sophisticated ways to measure attractiveness; e.g., we have not considered the attractiveness of the displayed result URL. Its length, bolding, and recognizable domain may have a significant impact.”
Source: Google, 2010
URL access, duration, frequency, and trajectory
Logged click data is not the only useful user behaviour signal. Session duration, for example, is a high-value metric if measured correctly. For example, a user could navigate to a page and leave it idle while they go out for lunch. This is where active user monitoring systems become useful.
“Abstract Web search components such as ranking and query suggestions analyze the user data provided in query and click logs. While this data is easy to collect and provides information about user behavior, it omits user interactions with the search engine that do not hit the server; these logs omit search data such as users’ cursor movements. Just as clicks provide signals for relevance in search results, cursor hovering and scrolling can be additional implicit signals.”Source: Microsoft, 2012
There are many assisting user-behaviour signals which, while not indexable, aid measurement of engagement time on pages. This includes various types of interaction via keyboard, mouse, touchpad, tablet, pen, touch screen, and other interfaces.
Google’s John Mueller recently explained that user engagement is not a direct ranking signal, and I believe this. Kind of. John said that this type of data (time on page, filling out forms, clicking, etc) doesn’t do anything automatically.
“So I’d see that as a positive thing in general, but I wouldn’t assume it is something that Google would pick up as a ranking factor and use to kind of promote your web site in search automatically.”
At this point in time, we’re likely looking at a sandbox model rather than a live listening and reaction system when it comes to the direct influence of user behaviour on a specific page. That said, Google does acknowledge limitations of quality-rater and sandbox-based result evaluation. They’ve recently proposed an active learning system, which would evaluate results on the fly with a more representative sample of their user base.
“Another direction for future work is to incorporate active learning in order to gather a more representative sample of user preferences.”
Google’s result attractiveness paper was published in 2010. In early 2011, Google released the Panda algorithm. Later that year, Panda went into flux, indicating an implementation of one form of an active learning system. We can expect more of Google’s systems to run on their own in the future.
The monitoring engine
Google has designed and patented a system in charge of collecting and processing of user behaviour data. They call it “the monitoring engine”, but I don’t like that name—it’s too long. Maybe they should call it, oh, I don’t know… Chrome?
The user behavior data might be obtained from a web browser or a browser assistant associated with clients. A browser assistant may include executable code, such as a plug-in, an applet, a dynamic link library (DLL), or a similar type of executable object or process that operates in conjunction with (or separately from) a web browser. The web browser or browser assistant might send information to the server concerning a user of a client.
Source: Ranking documents based on user behavior and/or feature data, Google, 2012
The actual patent describing Google’s monitoring engine is a truly dreadful read, so if you’re in a rush, you can read my highlights instead.
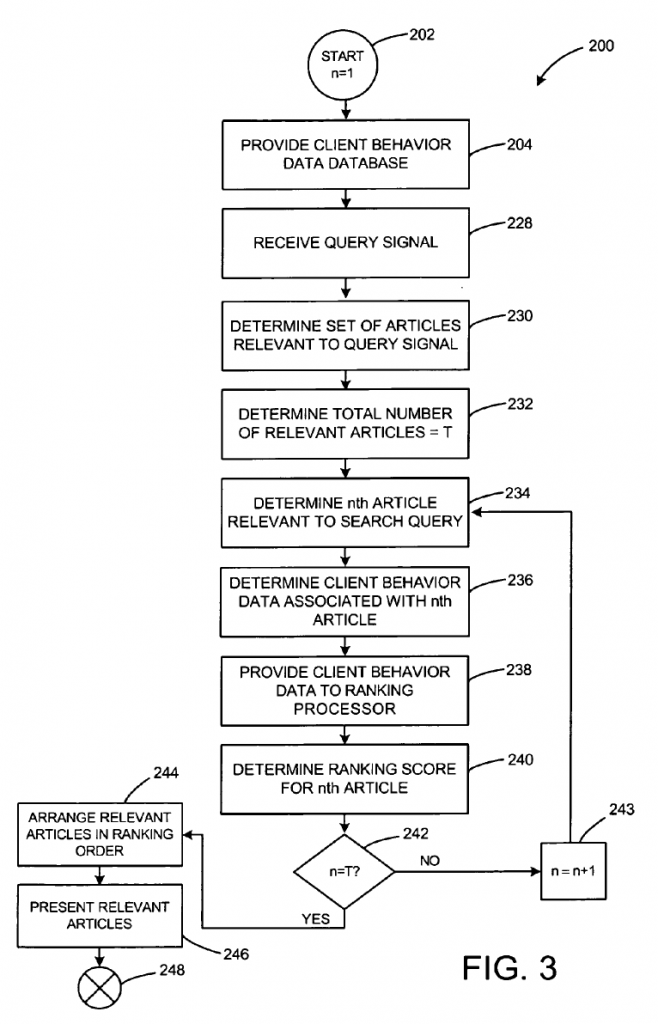
Google’s client behavior data processor can retrieve client-side behavior data associated with a web page.
This client-side behavior data can then be used to help formulate a ranking score for the article.
The monitoring engine can:
Distinguish whether the user is actually viewing an article, such as a web page, or whether the web page has merely been left active on the client device while the user is away from the client.
Monitor a plurality of articles associated with one or more applications and create client-side behavior data associated with each article individually.
Determine client-side behavior data for multiple user articles and ensure that the client-side behavior data associated with an article can be identified with that particular article.
Transmit the client-side behavior data, together with identifying information that associates the data with a particular article to which it relates, to the data store for storage in a manner that preserves associations between the article and the client behaviors.
Let’s step away from patents for a minute and observe what’s already out there. Chrome’s MetricsService is a system in charge of the acquisition and transmission of user log data. Transmitted histograms contain very detailed records of user activities, including opened/closed tabs, fetched URLs, maximized windows, et cetera.
Enter this in Chrome: chrome://histograms/
Here are some interesting variables to look up in your own list of histograms:
ET_KEY_PRESSED
ET_MOUSEWHEEL
ET_MOUSE_DRAGGED
ET_MOUSE_EXITED
ET_MOUSE_MOVED
ET_MOUSE_PRESSED
ET_MOUSE_RELEASED
MouseDown
MouseMove
MouseUp
BrowsingSessionDuration
NewTabPage.NumberOfMouseOvers
NewTabPage.SuggestionsType
NewTabPage.URLState
Omnibox.SaveStateForTabSwitch.UserInputInProgress
SessionRestore.TabClosedPeriod
SessionStorageDatabase.Commit
History.InMemoryTypedUrlVisitCount
Sync.FreqTypedUrls
Autofill.UserHappiness.
Examples of histogram usage:
The number of mousedown events detected at HTML anchor-tag links’ default event handler.
The HTTP response code returned by the Domain Reliability collector when a report is uploaded.
A count of form activity (e.g. fields selected, characters typed) in a tab. Recorded only for tabs that are evicted due to memory pressure and then selected again.
Track the different ways users are opening new tabs. Does not apply to opening existing links or searches in a new tab, only to brand-new empty tabs.
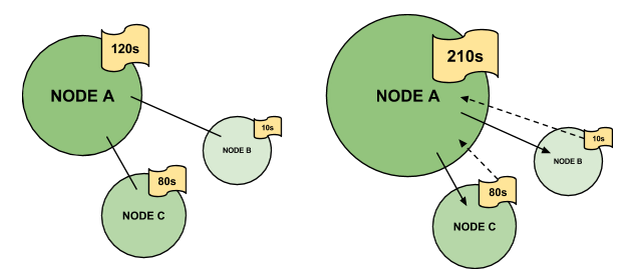
Google can process duration data in an eigenvector-like fashion using nodes (URLs), edges (links), and labels (user behaviour data). Page engagement signals, such as session duration value, are used to calculate weights of nodes. Here are the two modes of a simplified graph comprised of three nodes (A, B, C) with time labels attached to each:
In an undirected graph model (undirected edges), the weight of the node A is directly driven by the label value (120 second active session). In a directed graph (directed edges), node A links to node B and C. By doing so, it receives a time-label credit from the nodes it links to.
Duration data can comprise, for example, a network graph comprising nodes representing URLs visited by the user and edges representing connections between the URLs. The nodes can further comprise node labels that indicate how many times, how frequently, or how recently, for example, the user has visited the URL. A weight can be assigned to each node proportional to the node label and weights for nodes can be propagated to connected nodes.Source: Google, 2015
In plain English, if you link to pages that people spend a lot of time on, Google will add a portion of that “time credit” towards the linking page. This is why linking out to useful, engaging content is a good idea. A “client behavior score” reflects the relative frequency and type of interactions by the user.
Access data can include, for example, the number of times the user views an article or otherwise opens and enters into or interacts with an article. Additionally, access data can include a total number of days on which a document is accessed or edited by a user or a frequency of article access.Source: Google, 2015
What’s interesting is that the implicit quality signals of deeper pages also flow up to higher-level pages.
“Reasonable surfer” is the random surfer’s successor. The PageRank dampening factor reflects the original assumption that after each followed link, our imaginary surfer is less likely to click on another random link, resulting in an eventual abandonment of the surfing path. Most search engines today work with a more refined model encompassing a wider variety of influencing factors.
Examples of features associated with a link might include the font size of the anchor text associated with the link; the position of the link (measured, for example, in a HTML list, in running text, above or below the first screenful viewed on an 800×600 browser display, side(top, bottom, left, right) of document, in a footer, in a sidebar, etc.); if the link is in a list, the position of the link in the list; font color and/or attributes of the link (e.g., italics, gray, same color as background, etc.); number of words in anchor text associated with the link; actual words in the anchor text associated with the link; commerciality of the anchor text associated with the link; type of the link (e.g., image link); if the link is associated with an image (i.e., image link), the aspect ratio of the image; the context of a few words before and/or after the link; atopical cluster with which the anchor text of the link is associated; whether the link leads somewhere on the same host or domain; if the link leads to somewhere on the same domain, whether the link URL is shorter than the referring URL; and/or whether the link URL embeds another URL (e.g., for server-side redirection).
[…]
For example, model generating unit may generate a rule that indicates that links with anchor text greater than a particular font size have a higher probability of being selected than links with anchor text less than the particular font size. Additionally, or alternatively, model generating unit may generate a rule that indicates that links positioned closer to the top of a document have a higher probability of being selected than links positioned toward the bottom of the document. Additionally, or alternatively, model generating unit may generate a rule that indicates that when a topical cluster associated with the source document is related to a topical cluster associated with the target document, the link has a higher probability of being selected than when the topical cluster associated with the source document is unrelated to the topical cluster associated with the target document. These rules are provided merely as examples. Model generating unit may generate other rules based on other types of feature data or combinations of feature data. Model generating unit may learn the document-specific rules based on the user behavior data and the feature vector associated with the various links. For example, model generating unit may determine how users behaved when presented with links of a particular source document. From this information, model generating unit may generate document-specific rules of link selection.
For example, model generating unit may generate a rule that indicates that a link positioned under the “More Top Stories” heading on the cnn.com web site has a high probability of being selected. Additionally, or alternatively, model generating unit may generate a rule that indicates that a link associated with a target URL that contains the word “domainpark” has a low probability of being selected. Additionally, or alternatively, model generating unit may generate a rule that indicates that a link associated with a source document that contains apopup has a low probability of being selected. Additionally, or alternatively, model generating unit may generate a rule that indicates that a link associated with a target domain that ends in “.tv” has a low probability of being selected. Additionally, or alternatively, model generating unit may generate a rule that indicates that a link associated with a target URL that includesmultiple hyphens has a low probability of being selected.
Source: Google, 2012
For example, the likelihood of a link being clicked on within a page may depend on:
Position of the link on the page (top, bottom, above/below fold)
Location of the link on the page (menu, sidebar, footer, content area, list)
In addition to perceived importance from on-page signals, a search engine may judge link popularity by observing common user choices. A link on which users click more within a page can carry more weight than the one with less clicks. Google in particular mentions user click behaviour monitoring in the context of balancing out traditional, more manipulative signals (e.g. links).
The user behavior data may include, for example, information concerning users who accessed the documents, such as navigational actions (e.g., what links the users selected, addresses entered by the users, forms completed by the users, etc.), the language of the users, interestsof the users, query terms entered by the users, etc.Source: Google, 2012
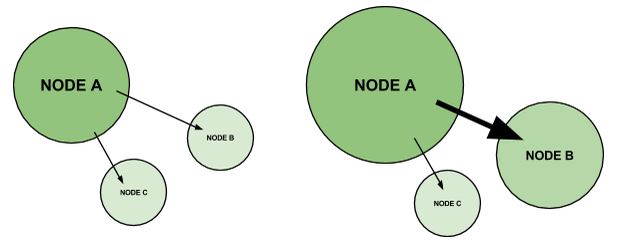
In the following illustration, we can see two outbound links on the same document (A) pointing to two other documents: (B) and (C). On the left is what would happen in the traditional “random surfer model,” while on the right we have a link which sits on a more prominent location and tends to be a preferred choice by many of the pages’ visitors.
This method can be used on a single document or in a wider scope, and is also applicable to both single users (personalisation) and groups (classes) of users determined by language, browsing history, or interests.
For example, the web browser or browser assistant may record data concerning the documents accessed by the user and the links within the documents (if any) the user selected. Additionally, or alternatively, the web browser or browser assistant may record data concerning the language of the user, which may be determined in a number of ways that are known in the art, such as by analyzing documents accessed by the user. Additionally, or alternatively, the web browser or browser assistant may record data concerning interests of the user. This may be determined, for example, from the favorites or bookmark list of the user, topics associated with documents accessed by the user, or in other ways that are known in the art. Additionally, or alternatively, the web browser or browser assistant may record data concerning query terms entered by the user. The web browser or browser assistant may send this data for storage in repository.
Source: Google, 2012
Pogo-sticking
One of the most telling signals for a search engine is when users perform a query and quickly bounce back to search results after visiting a page that didn’t satisfy their needs. The effect was described and discussed a long time ago, and numerous experiments show its effect in action. That said, many question the validity of SEO experiments largely due to their rather non-scientific execution and general data noise. So, it’s nice to know that the effect has been on Google’s radar.
Additionally, the user can select a first link in a listing of search results, move to a first web page associated with the first link, and then quickly return to the listing of search results and select a second link. The present invention can detect this behavior and determine that the first web page is not relevant to what the user wants. The first web page can be down-ranked, or alternatively, a second web page associated with the second link, which the user views for longer periods or time, can be up-ranked.
Source: Google, 2015
Address bar
URL data can include whether a user types a URL into an address field of a web browser, or whether a user accesses a URL by clicking on a hyperlink to another web page or a hyperlink in an email message. So, for example, if users type in the exact URL and hit enter to reach a page, that represents a stronger signal than when visiting the same page after a browser autofill/suggest or clicking on a link.
Typing in full URL (full significance)
Typing in partial URL with auto-fill completion (medium significance)
Following a hyperlink (low significance)
Login pages
Google monitors users and maps their journey as they browse the web. They know when users log into something (e.g. social network) and they know when they end the session by logging out. If a common journey path always starts with a login page, Google will add more significance to the login page in their rankings.
“A login page can start a user on a trajectory, or sequence, of associated pages and may be more significant to the user than the associated pages and, therefore, merit a higher ranking score.”
I find this very interesting. In fact, as I write this, we’re setting up a login experiment to see if repeated client access and page engagement impacts the search visibility of the page in any way. Readers of this article can access the login test page with username: moz and password: moz123.
The idea behind my experiment is to have all the signals mentioned in this article ticked off:
URL familiarity, direct entry for maximum credit
Triggering frequent and repeated access by our clients
Expected session length of 30-120 seconds
Session length credit up-flow to home page
Interactive elements add to engagement (export, chart interaction, filters)
Combining implicit and traditional ranking signals
Google treats various user-generated data with different degrees of importance. Combining implicit signals such as day of the week, active session duration, visit frequency, or type of article with traditional ranking methods improves reliability of search results.
The ranking processor determines a ranking score based at least in part on the client-side behavior data, retrieved from the client behavior data processor, associated with the nth article. This can be accomplished, for example, by a ranking algorithm that weights the various client behavior data and other ranking factors associated with the query signal to produce a ranking score. The different types of client behavior data can have different weights, and these weights can be different for different applications. In addition to the client behavior data, the ranking processor can utilize conventional methods for ranking articles according to the terms contained in the articles. It can further use information obtained from a server on a network (for example, in the case of web pages). The ranking processor can request a PageRank value for the web page from a server and additionally use that value to compute the ranking score. The ranking score can also depend on the type of article. The ranking score can further depend on time, such as the time of day or the day of the week. For example, a user can typically be working on and interested in certain types of articles during the day, and interested in different kinds of articles during the evening or weekends.
Source: Google, 2015
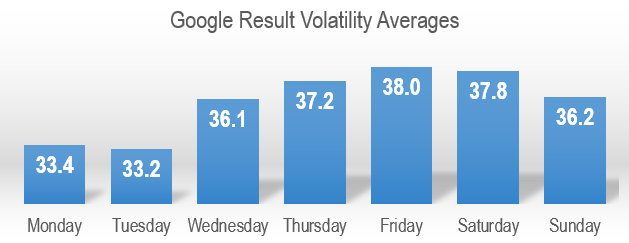
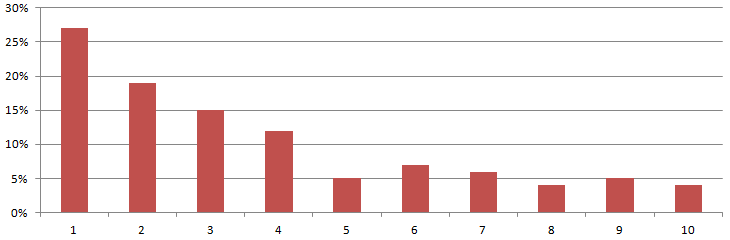
I first suspected Google’s results change in regular patterns (weekdays, weekends, seasonal events) back in 2013. In a follow-up study this year, we analysed the last 186 days of Algoroo volatility data. Our results showed behaviourally-triggered changes trending from Wednesday onward, usually peaking around Friday and Saturday with a small decline on Sunday and a dramatic drop at the beginning of the week:
Values presented in the chart above are a sum of daily volatility scores for each day of the week during the observation period of 186 days. Our daily fluctuation values are aggregated from result movement, factoring in ~17,000 keywords, 100 deep.
Impact on SEO
The fact that behaviour signals are on Google’s radar stresses the rising importance of user experience optimisation. Our job is to incentivise users to click, engage, convert, and keep coming back. This complex task requires a multidisciplinary mix, including technical, strategic, and creative skills. We’re being evaluated by both users and search engines, and everything users do on our pages counts. The evaluation starts at the SERP level and follows users during the whole journey throughout your site.
“Good user experience”
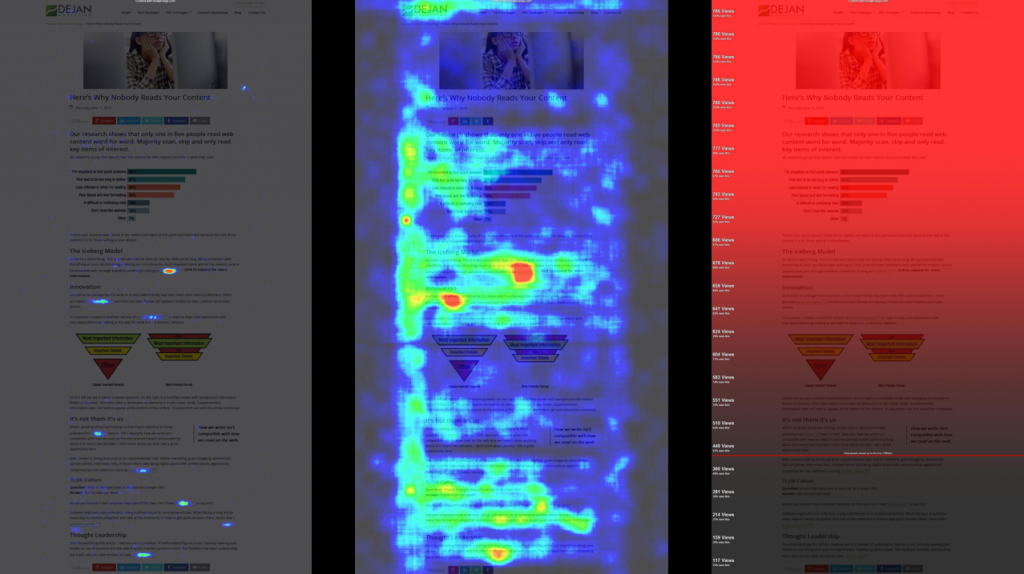
Search visibility will never depend on subjective user experience, but on search engines’ interpretation of it. Our most recent research into how people read online shows that users don’t react well when facing large quantities of text (this article included) and will often skim content and leave if they can’t find answers quickly enough. This type of behaviour may send the wrong signals about your page.
My solution was to present all users with a skeletal content form with supplementary content available on-demand through use of hypotext. As a result, our test page (~5000 words) increased the average time per user from 6 to 12 minutes and bounce rate reduced from 90% to 60%. The very article where we published our findings shows clicks, hovers, and scroll depth activity of double or triple values to the rest of our content. To me, this was convincing enough.
Google’s algorithms disagreed, however, devaluing the content not visible on the page by default. Queries contained within unexpanded parts of the page aren’t bolded in SERP snippets and currently don’t rank as well as pages which copied that same content but made it visible. This is ultimately something Google has to work on, but in the meantime we have to be mindful of this perception gap and make calculated decisions in cases where good user experience doesn’t match Google’s best practices.
Dan Petrovic, the managing director of DEJAN, is Australia’s best-known name in the field of search engine optimisation. Dan is a web author, innovator and a highly regarded search industry event speaker.
ORCID iD: https://orcid.org/0000-0002-6886-3211