
Enhancing Search Re-Ranking by Boosting Rare Features
In information retrieval, ranking search results is a critical task. Traditional methods often prioritize common features, which can lead to generic results. A novel approach to address this involves boosting rare features within the embedding space to improve re-ranking. This method emphasizes uniqueness and relevance, particularly in large datasets where common features may dominate.How It Works
When a user submits a query, the system generates an embedding—a numerical representation of the query’s meaning. Similarly, the documents or results in the database are also represented as embeddings. The standard approach calculates the similarity between the query embedding and document embeddings, ranking the results based on this similarity. However, this conventional method tends to favor features that are common across many documents. While this can surface broadly relevant results, it risks overlooking documents with rare, yet potentially more significant, features.The Role of Rare Features
Rare features are those elements in the embedding that occur infrequently across the dataset. They might represent niche topics or unique combinations of ideas. By boosting these rare features, the re-ranking algorithm can give more weight to documents that match the query in these less common but more specific ways. This boosting process involves the following steps: Embedding Generation The query and documents are converted into embeddings using a pre-trained model.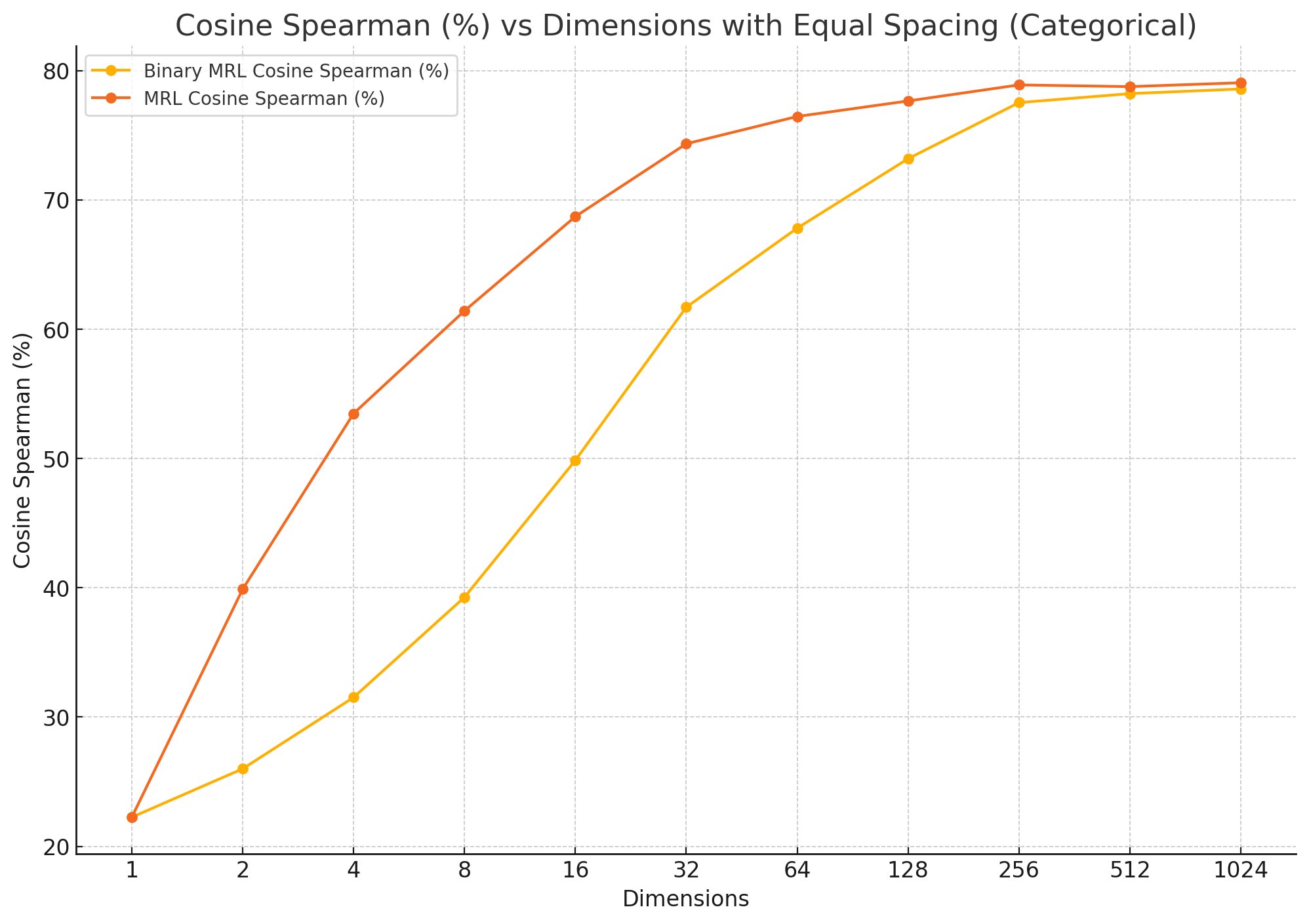 Binary Quantization and MRL Truncation
These techniques are used to compress the embeddings, making the process more efficient while retaining the essential information.
Binary Quantization and MRL Truncation
These techniques are used to compress the embeddings, making the process more efficient while retaining the essential information.
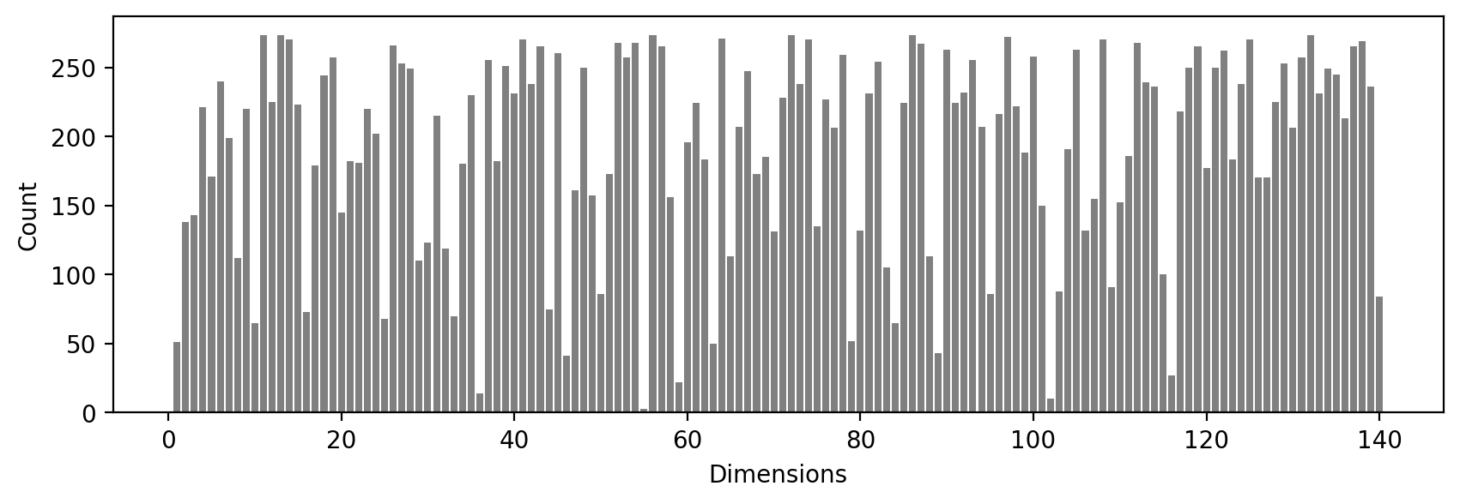
 Feature Frequency Calculation
The frequency of each feature across all document embeddings is calculated. Features that appear less frequently are identified as rare.
Feature Frequency Calculation
The frequency of each feature across all document embeddings is calculated. Features that appear less frequently are identified as rare.
 Bidirectional Scaling
The embeddings are adjusted by scaling up the importance of rare features. This is done using a scale factor that increases the weight of these features in the similarity calculation. This technique adjusts the embeddings by promoting rare features, enhancing their impact on the final similarity score while implicitly reducing the impact of the more common features.
Bidirectional Scaling
The embeddings are adjusted by scaling up the importance of rare features. This is done using a scale factor that increases the weight of these features in the similarity calculation. This technique adjusts the embeddings by promoting rare features, enhancing their impact on the final similarity score while implicitly reducing the impact of the more common features.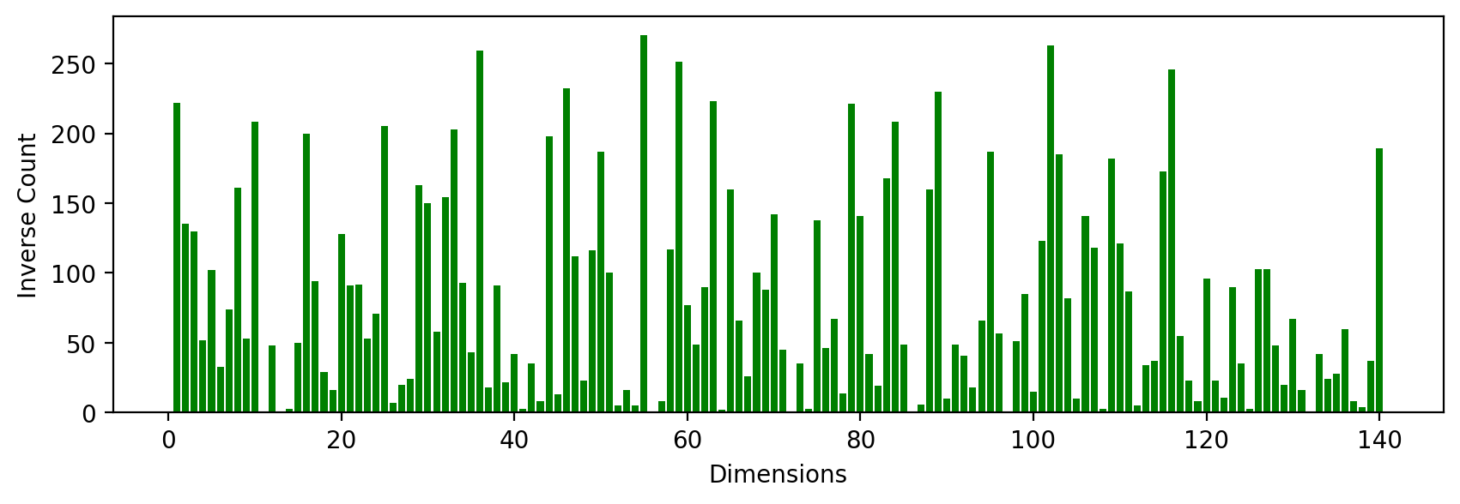 Re-ranking
The documents are re-ranked based on the adjusted similarity scores, which now prioritize documents with a higher presence of rare features matching the query.
Re-ranking
The documents are re-ranked based on the adjusted similarity scores, which now prioritize documents with a higher presence of rare features matching the query.
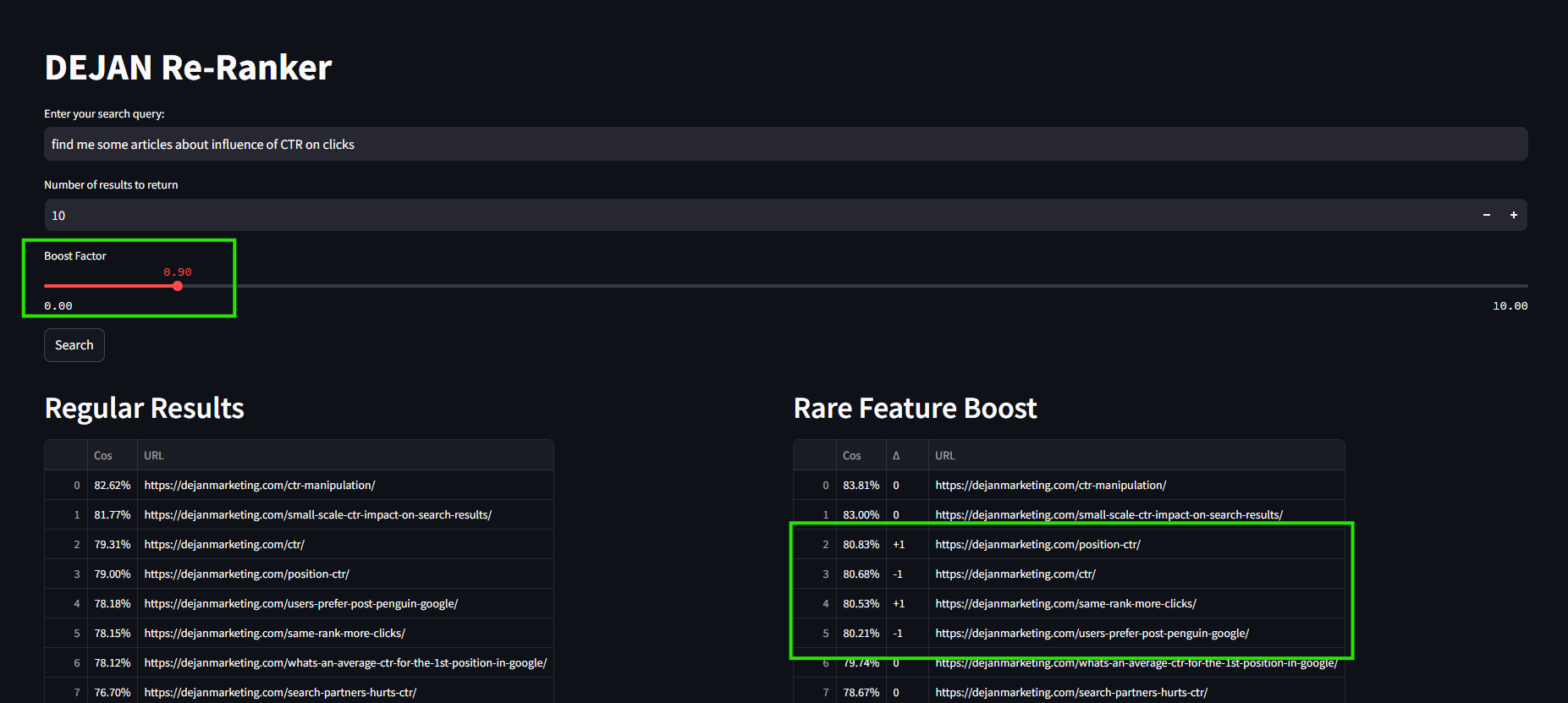
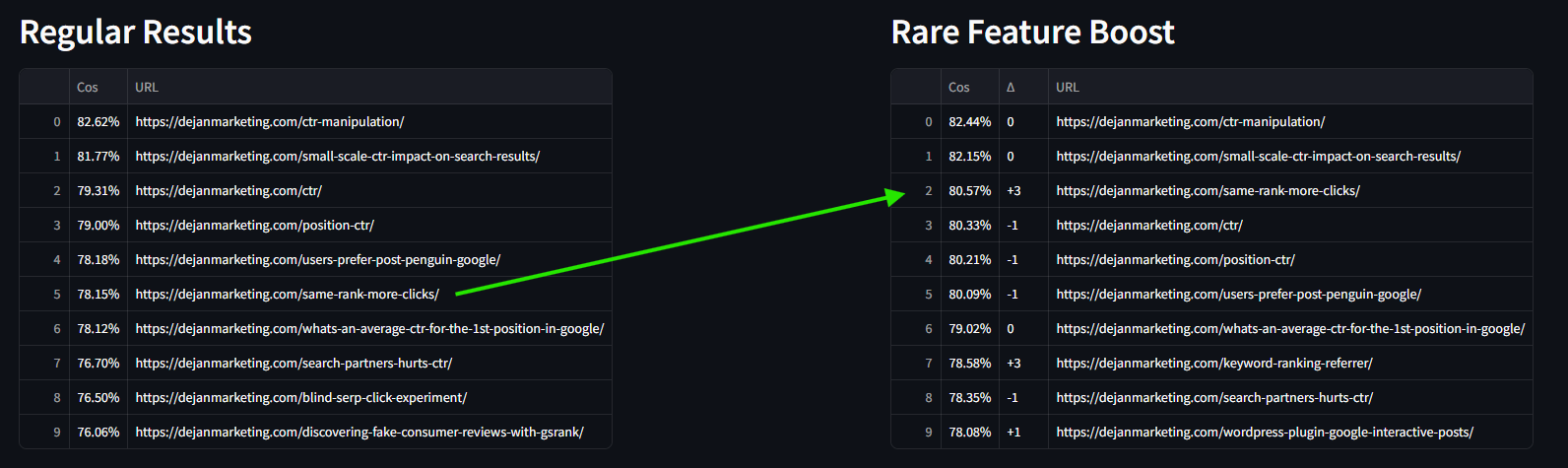 Visualization and Analysis
Tools like rank change visualization and feature frequency plots help in understanding how the re-ranking affects the results and in fine-tuning the scaling process.
Visualization and Analysis
Tools like rank change visualization and feature frequency plots help in understanding how the re-ranking affects the results and in fine-tuning the scaling process.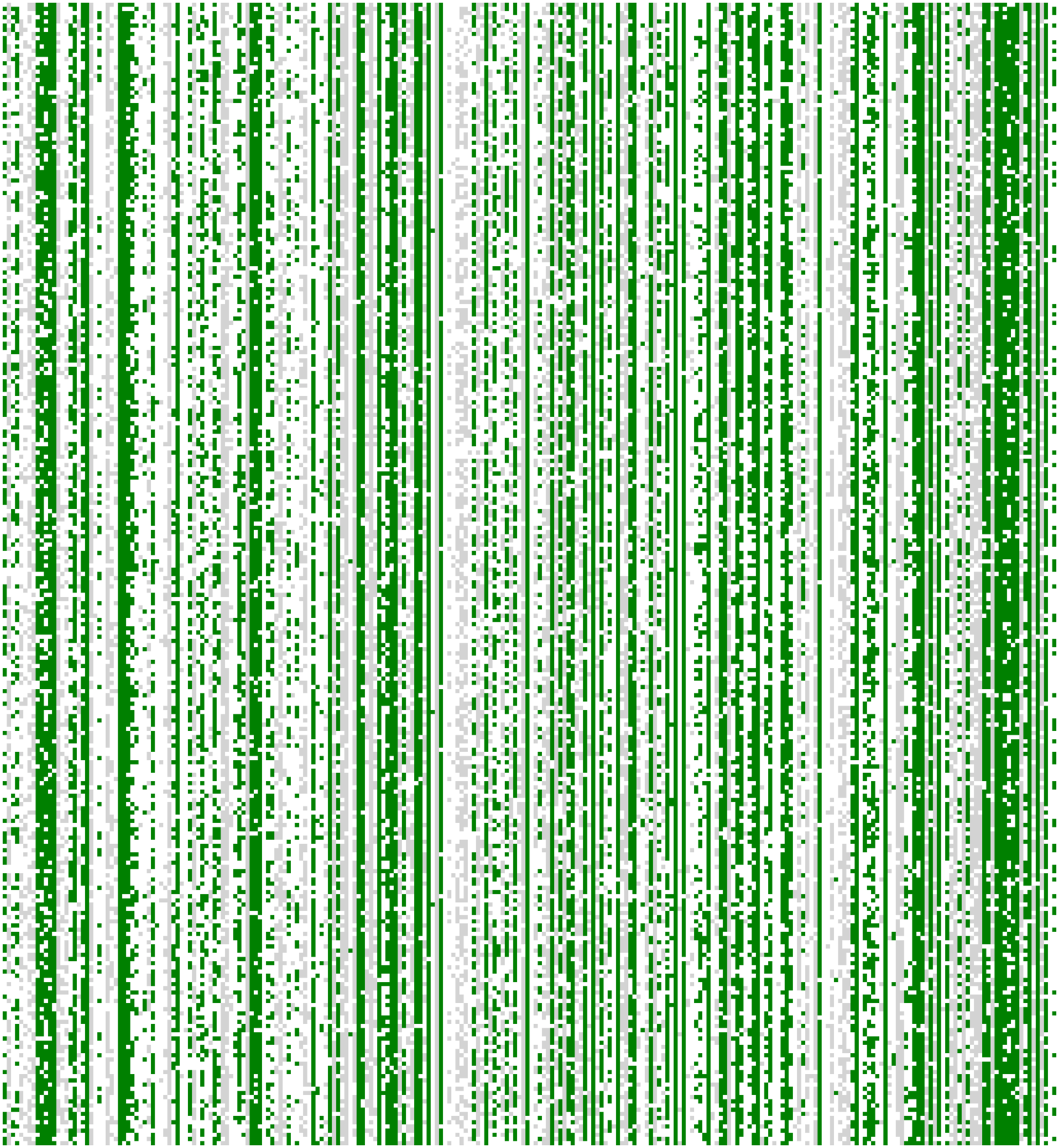
Results and Benefits
By applying this technique, search systems can surface results that are not only relevant but also unique and insightful. This is particularly valuable in specialized domains where specific, uncommon features are more critical than broad relevance.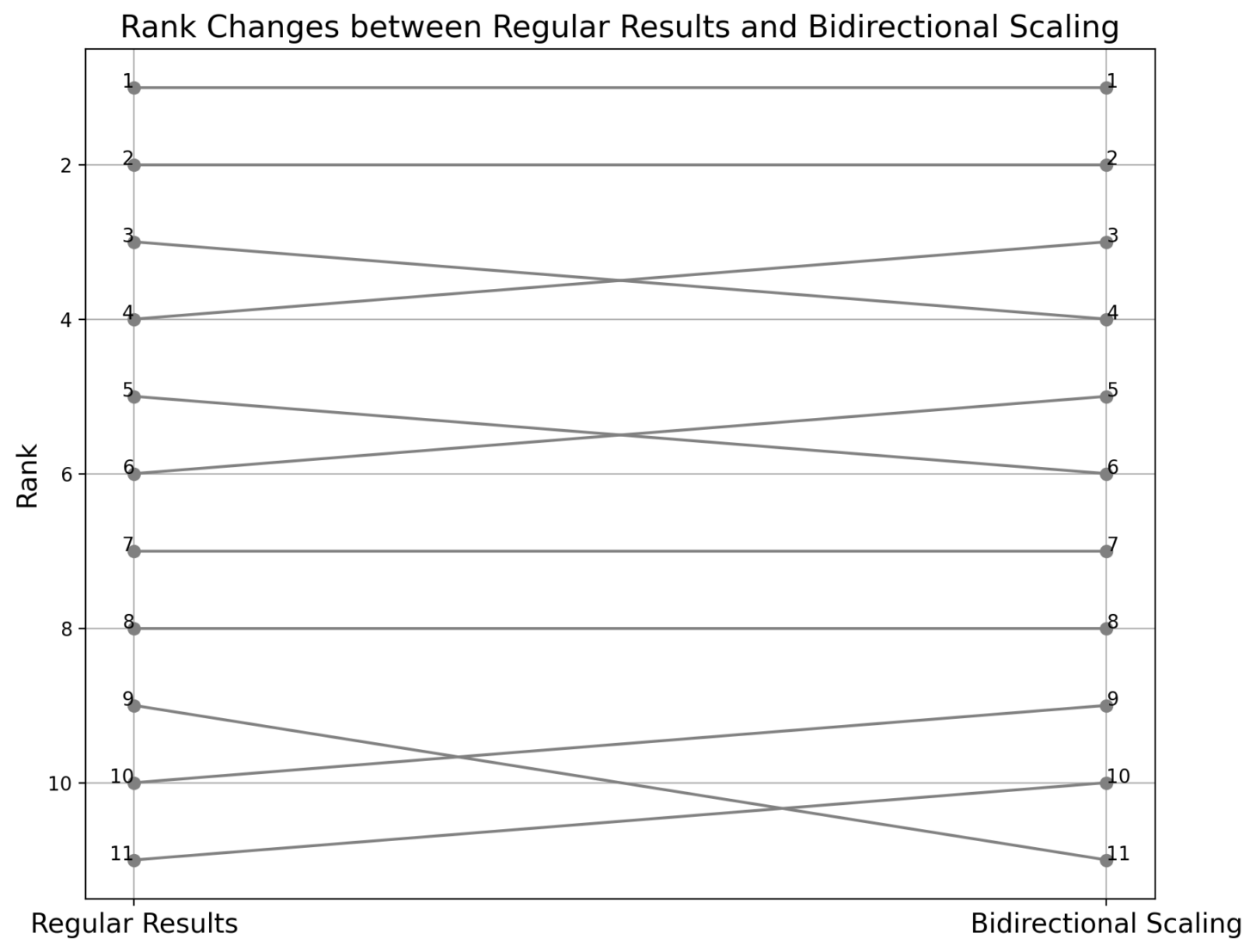 Boosting rare features in the re-ranking process is a powerful method for improving the quality of search results. It addresses the limitations of traditional ranking algorithms by ensuring that unique and relevant content is more likely to appear at the top of the search results.
Papers:
Boosting rare features in the re-ranking process is a powerful method for improving the quality of search results. It addresses the limitations of traditional ranking algorithms by ensuring that unique and relevant content is more likely to appear at the top of the search results.
Papers:
Dan Petrovic, the managing director of DEJAN, is Australia’s best-known name in the field of search engine optimisation. Dan is a web author, innovator and a highly regarded search industry event speaker.
ORCID iD: https://orcid.org/0000-0002-6886-3211

Previous Article
